Code Organization
Context: I work in projects for customers. Mostly involving Ansible and Terraform. These customer range in size from about 100 employees to 100.000 employees.
Code organization?
After learning and adopting a technology, like Terraform on Ansible, a question that will come up is: “How do we structure all that code in a maintainable way?”. With this article I hope to explain what options there are and which option usually works.
NOTE: This is not exact science. This is my opinion and experience. I’m sure there are other ways to do this, with good reasons.
The organization types
I mostly see these types of organizations:
- “TECH ORIENTED” - There are departments like
network,linux,windows,databasesand so on. Departments depend on each other, adatabaseneeds to be installed on for examplelinux, which needs to be on anetwork. - “SERVICE ORIENTED” - There are departments based on business value, for example
mobile-app,morgages,parts-warehouse,it-support. These departments can be completely independent from each other, having their own release cycles and an outage to one service, does not affect the other services. - “ENVIRONMENT ORIENTED” - Much less common, but there are
development,testingandproductiondepartments. Knowledge of all services is requied at eacht department. An “environment” can be broken, not influencing the other environments. (These departments can also be perdatacenter,cloudorcountryfor example.)
Decide
I’ve tried to draw (Yes, artschool does pay off.) a decision chart to help you decide which organization type to choose.
[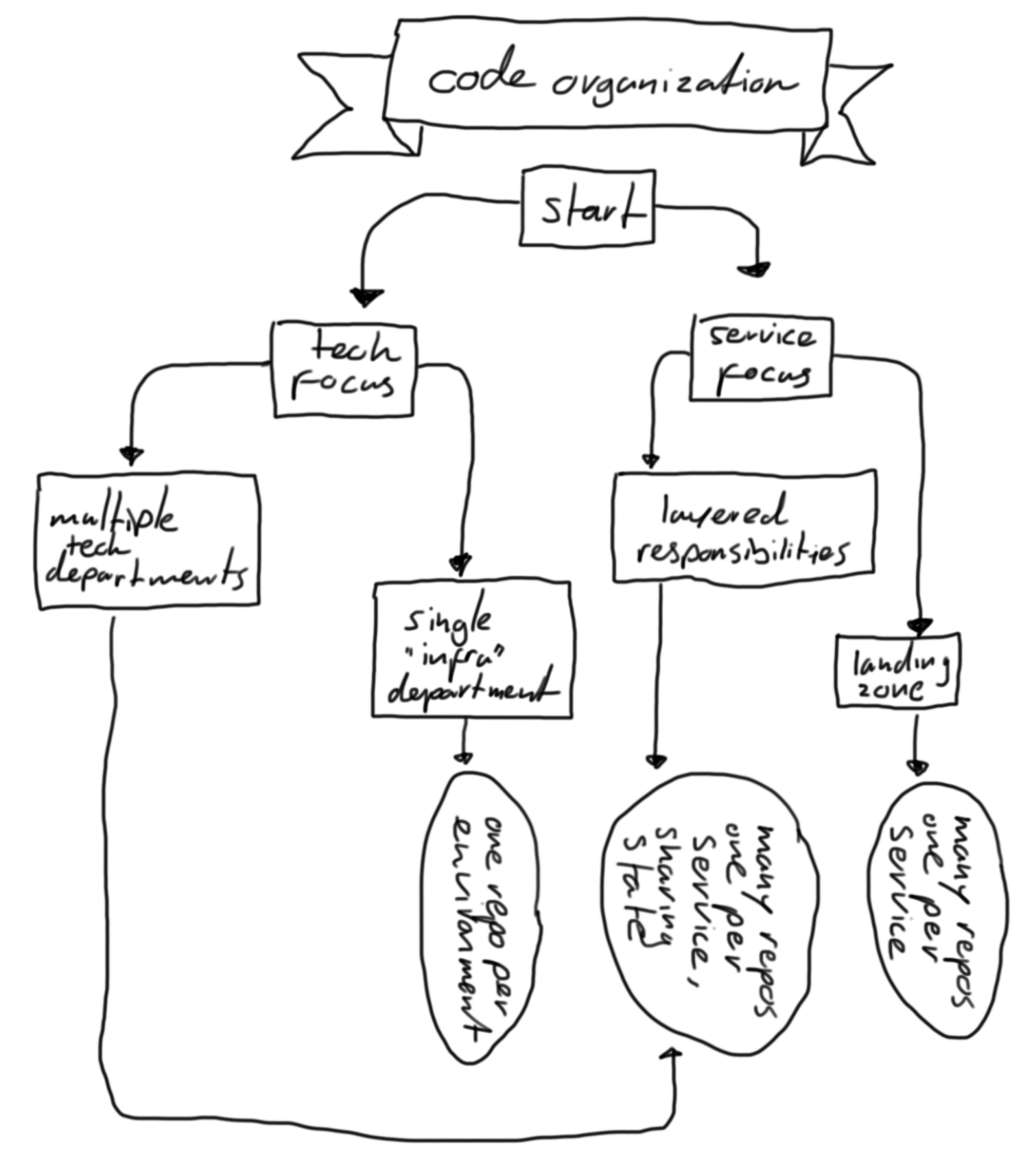 ]
]
The outcome contains a few of terms that need more explanation:
- “ONE REPO PER ENVIRONMENT” - Here, a single department maintains all code to provision and configure infrastructure. Typical for a smaller company with a couple of “system administrators”. In this situation, the blast-radius of a mistake can be huge.
- “MANY REPOS, ONE PER SERVICE, SHARING STATE” - This means that each service has it’s own repository, but they need something from each other. For example, the
networkis shared, so as a department, you should connect to the currect subnets. - “MANY REPOS, ONE PER SERVICE” - This means that each service has it’s own repository. This is a good way to go if you have a lot of services and they are not dependent on each other. This way you can have a release cycle per service.
My opinion
- For a small company, I would go with “ONE REPO PER ENVIRONMENT”. This is the easiest to maintain and understand. The blast-radius is a worry, so testing and roll-back scenarios are important.
- For ambitious organizations, growing fast, I would go with “MANY REPOS, ONE PER SERVICE, SHARING STATE”. This way you can have a release cycle per service, but still have the ability to re-use components like
networkresources. [ ] For larger organizations, I would go with “MANY REPOS, ONE PER SERVICE”. This way you can have a release cycle per service and you can have a lot of services without the need to re-use components. The pay-off here is that there will be more infastucture and more people with knowledge about similar resources. This is the most scalable model though.
Hope this information helps a bit in deciding how to setup your repositories.